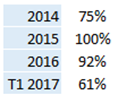Afin de se placer en « situation réelle », nous avons effectué plusieurs « backtesting » :
(1) apprentissage sur 1990 à 2007, validation sur 2008 & 2009, et évaluation sur 2010 à 2012,
(2) apprentissage sur 1990 à 2010, validation sur 2011 & 2012 et évaluation sur 2013 à 2015,
(3) apprentissage sur 1990 à 2013, validation sur 2014 & 2015 et évaluation sur 2016 à 2018.
La « validation » est couplée à l’apprentissage pour classer au préalable les performances des modèles construits.
Pour chacun des 3 cas nous avons construit plusieurs milliers de réseaux de neurones (RN) et déterminé le meilleur « multi-modèle » (i.e. utilisation de plusieurs RN par vote démocratique), grâce à notre algorithme de forêt neuronale, voir l’article sur notre page des use cases le concernant. L’évaluation de performance s’effectue par « précision », à savoir le % de bonnes prédictions de la bonne classe.
Les deux premiers backtesting ont montré des niveaux de précisions supérieurs à 90% en apprentissage, et de 85% sur les 12 mois suivants, avec une baisse de précision de l’ordre de 15% les 24 mois suivant. Sans rentrer dans les détails, nous avons alors indiqué que la « profondeur » des données n’étant pas suffisante, un réapprentissage annuel semblait souhaitable.
Le troisième backtesting l’a démontré de façon encore plus évidente. La précision du multi-modèle sur la période d’apprentissage 1990 à 2015 est restée supérieure à 90% comme dans les 2 précédents backtestings, mais sur 2016 à 2018 elle chute à 45% (avec un niveau de 57% sur les 12 premiers mois). La raison en est simple : après analyse des données, on constate que le comportement myopique des années 2016à2018 est « extrémal » au regard des années précédentes.
Donnons-en une illustration simple, en utilisant une projection 2D de type « t-SNE » (disponible via notre logiciel gratuit DEXTER) de la base de données :