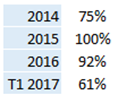We decided to opt for 3 “back-testing” approaches :
(1) training on 1990->2007, validation on 2008 & 2009, evaluation on 2010->2012,
(2) training on 1990->2010, validation on 2011 & 2012, evaluation on 2013->2015,
(3) training on 1990->2013, validation on 2014 & 2015, evaluation on 2016->2018.
Validation is coupled with training in order to rank all forecast models in all the 3 back-testing scenarios; evaluation is used for the final assessment of performances.
For each of these back-testing scenarios, we built two thousand deep neural networks (NN) and selected the best “neural forest” (that is the best small subset of NNs, used to define the final forecast value by using democratic votes), see the related article on NEHOOV (french) use cases pages. Assessment of performance uses average accuracy.
Our two first back-testing scenario showed accuracy above 90% on the training set, 85% for the next 12 months, and 70% for months 13 to 24. We explained to our client that since the « deepness » of the database was not enough, a yearly retraining seems mandatory.
The last back-test proved this point more deeply. Accuracy of the best neural forest on the training set 1990->2015 stayed above 90% (as for the two last back-testing scenarios), but dropped to 45% on 2016->2018 (with a level of 57% on the first 12 months of 2016). The reason is simple : looking at all the monthly data, it appeared that records for months 2016->2018 are outliers regarding prior years. For illustration, let’s use a 2D-projection of the whole database, for instance by using t-SNE (a feature of our free tool DEXTER):